
Erkennungsergebnisse von Deep-Learning verbessern
Labeling in Deep-Learning-basierten Machine-Vision-Anwendungen
Entscheidend für den Erfolg eines kamerabasierten Inspektionssystems mit Deep Learning und damit einen klaren Wettbewerbsvorteil ist letztendlich die Qualität der Daten. Hierbei unterscheiden sich Deep-Learning-Technologien fundamental von klassischen, regelbasierten Ansätzen. Denn bei Ersteren müssen zunächst in großem Umfang Daten gesammelt, organisiert und annotiert werden, bevor die eigentliche Entwicklung der Anwendung beginnen kann. Zwar ist bei vielen Deep-Learning-Projekten ein schneller Erfolg in der Anfangsphase zu beobachten. Dennoch zeigt sich im späteren Verlauf häufig, dass sich lediglich Erkennungsraten von maximal 95 Prozent realisieren lassen. Auch ein extensives Tuning der Trainingsparameter oder das Testen diverser Netzwerkarchitekturen ist meist nicht erfolgversprechend. Die Ursache hierfür liegt darin, dass die Datengrundlage und deren Aufbereitung das Problem nicht korrekt beschreibt. Das bedeutet, die Qualität der Datensätze ist mangelhaft.
-
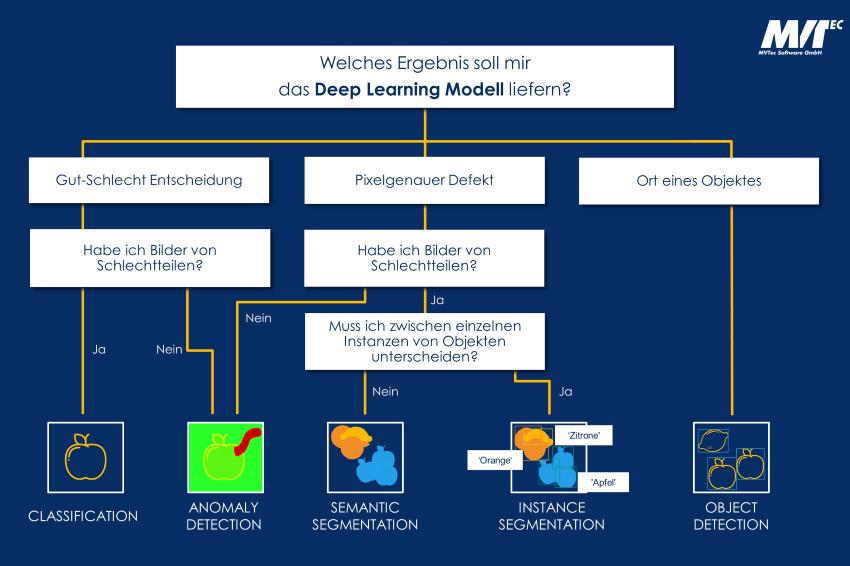 Die Auswahl der Deep-Learning-Methode orientiert sich an der Problembeschreibung. Bild: MVTec
Die Auswahl der Deep-Learning-Methode orientiert sich an der Problembeschreibung. Bild: MVTec -
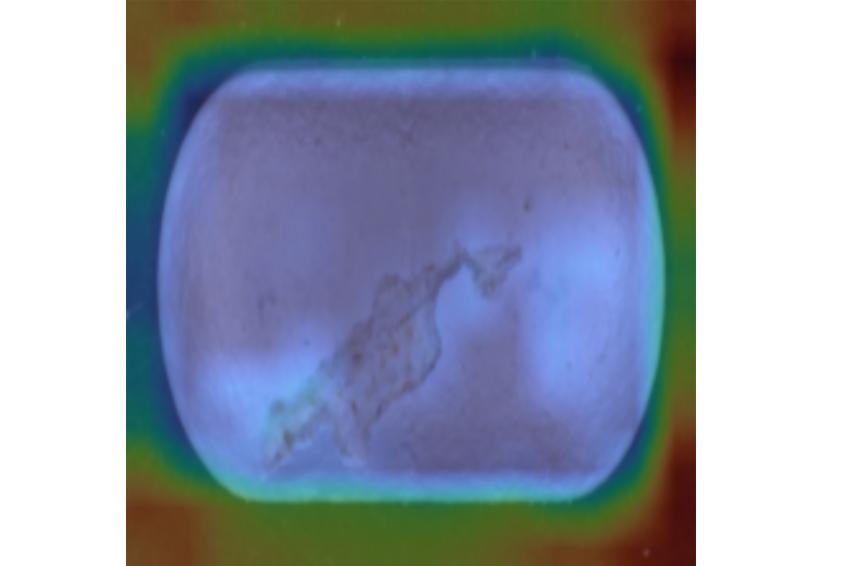 Heatmap: Häufig kommt es bei Deep-Learning-Projekten zum Overfitting: Dabei lernt der Algorithmus nicht, die Objekte zu unterscheiden, sondern Bildeigenschaften, wie in diesem Fall den Hintergrund. Bild: MVTec
Heatmap: Häufig kommt es bei Deep-Learning-Projekten zum Overfitting: Dabei lernt der Algorithmus nicht, die Objekte zu unterscheiden, sondern Bildeigenschaften, wie in diesem Fall den Hintergrund. Bild: MVTec -
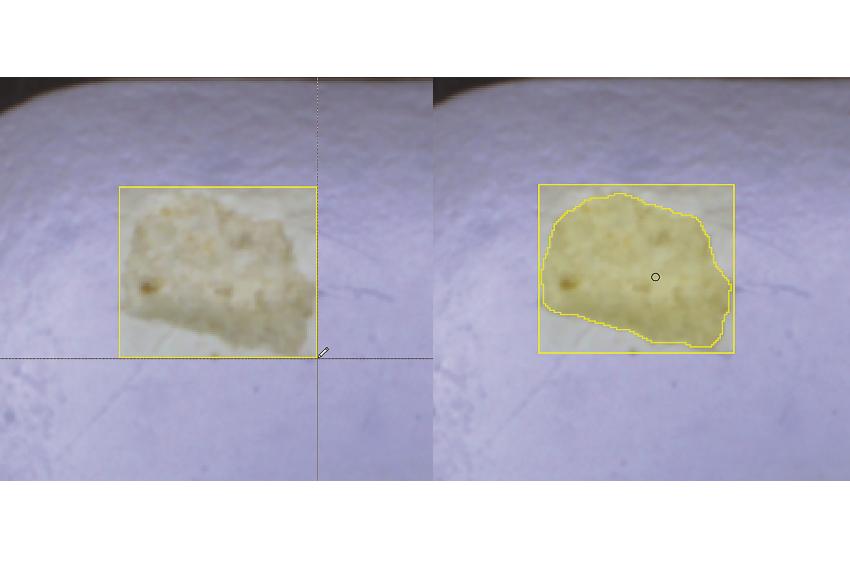 Das Deep Learning Tool von MVTec schlägt automatisch ein Label vor (rechte Bildhälfte). Bild: MVTec
Das Deep Learning Tool von MVTec schlägt automatisch ein Label vor (rechte Bildhälfte). Bild: MVTec
Welche Deep-Learning-Methode eignet sich?
Daher investieren Deep-Learning-Projektteams in der Regel bis zu 80 Prozent ihrer Zeit darin, das Niveau der Datenqualität signifikant anzuheben. Dieses Vorgehen gliedert sich in mehrere Schritte: Zunächst ist präzise zu beschreiben, nach welcher Art von Defekt gesucht wird. Dabei müssen mehrere Parameter definiert werden:
- Wird eine Einteilung in „gute/schlechte Qualität“ benötigt?
- Ist ein Objekt zu lokalisieren?
- Soll ein Defekt im Bild segmentiert werden, das heißt, sollen dem Fehler bestimmte Pixel im Bild zugeordnet werden?
- Gibt es bereits Bilder von fehlerbehafteten Teilen?
- Oder ist im Zeitpunkt der Entwicklung noch gar nicht bekannt, welche Defekte konkret auftreten können?
Nach Klärung dieser Fragen kann die richtige Deep-Learning-Methode ausgewählt werden, also Classification, Anomaly Detection, Segmentation, Instance Segmentation oder Object Detection.
Labeling benötigt viel Zeit
Nach der Beschreibung der Problemstellung beginnt das eigentliche Datenmanagement. Zunächst muss eine ausreichende Menge valider Daten erstellt und gesammelt werden. Hierbei ist in der Bildverarbeitung darauf zu achten, dass die Bilder unter realistischen Produktionsbedingungen aufgenommen werden. So müssen beispielsweise die Varianz der Beleuchtung durch Tageslichteinflüsse, unregelmäßige Hintergründe oder unterschiedliche Oberflächen kontrolliert oder im Datensatz erfasst sein. Dabei nimmt das Labeling den größten Teil des Datenmanagements und des gesamten Deep-Learning-Projektes in Anspruch.
Wodurch erklärt sich nun die hohe Bedeutung des Labelings? Lernende Systeme auf Basis von Künstlicher Intelligenz (KI) wie Deep Learning funktionieren meistens nach dem sogenannten Supervised-Ansatz. Deutlich wird dies an folgendem Beispiel: Ein Schüler erhält vom Lehrer eine bestimmte Aufgabe. In einem iterativen Prozess versucht nun der Schüler, das Problem in mehreren Schritten zu lösen (Training). Nach jedem Zyklus setzen sich Lehrer und Schüler zusammen und erarbeiten gemeinsam eine Strategie zur Verbesserung (Validation). Nach einer ausreichenden Anzahl von Zyklen steht die Prüfung an: Der Schüler bekommt eine ihm bisher unbekannte Aufgabe, um den Lernerfolg zu überprüfen (Test). Diese Analogie verdeutlicht die zentrale Rolle des Labelings: Dieses bringt wie ein Lehrer wichtige neue Informationen in das System, die das Lernen erst ermöglichen und damit den Weg für eine korrekte Entscheidung ebnen.
Labeling-Aufwand hängt von der Deep-Learning-Methode ab
Wie das Lehren im echten Leben lässt sich auch das Labeln nicht automatisieren. Daher entsteht vor allem bei großen Bildmengen ein sehr hoher manueller Aufwand, der jedoch stark von der jeweils verwendeten Methode abhängt. Bei Unsupervised-Methoden wie etwa Anomaly Detection lernt das Netzwerk anhand von Umweltfaktoren, also nicht explizit durch einen Lehrer. Hier werden ausschließlich fehlerfreie Teile für das Training benötigt. Dabei lernt das Deep-Learning-Netz, Abweichungen von den „guten Teilen“ zu erkennen. Bei einer Supervised-Methode, der Classification, steigt der Aufwand, da hier alle Trainingsbilder in Klassen eingeteilt werden. Bei der Object Detection wiederum müssen Objekte innerhalb jedes Bildes markiert werden, was den Aufwand für das Labeling zusätzlich erhöht. Am aufwändigsten gestaltet sich die Segmentation, da hier die Pixel eines Bildes in einzelne Klassen wie Objekt oder Hintergrund zugeordnet werden müssen.
So scheitern Deep-Learning-Projekte häufig am hohen Labeling-Aufwand und der Komplexität des Qualitätsmanagements. Dabei bilden die richtigen Daten, korrektes Labeling und eine hohe Datenqualität die Grundvoraussetzungen für ein erfolgreiches Projekt. Wertvolle Unterstützung bietet hier eine Toolchain wie beispielsweise das MVTec Deep Learning Tool in Kombination mit Halcon. Es trägt aktiv dazu bei, den Aufwand für das Labeling zu verringern und hilft Anwendern, Fehler sowie Unregelmäßigkeiten im Datensatz sicher zu finden.
Wichtige Funktionen einer Deep-Learning-Toolchain
Um die Datenqualität zu erhöhen und zugleich den Aufwand zu reduzieren, sollte die Toolchain bestimmte Funktionen umfassen. Dazu gehört eine Labeling Guideline. Darüber hinaus sollte das Tool Rückschlüsse auf die Zusammensetzung des Datensatzes wie etwa die Klassenverteilung innerhalb der Splits zulassen. Ein weiteres wichtiges Feature ist die Heatmap. Denn häufig kommt es bei Deep- Learning-Projekten zum sogenannten Overfitting: Manchmal variieren bestimmte Eigenschaften eines Bildes wie etwa der Hintergrund eines Objektes oder Bildrauschen nicht zufällig, sondern gemeinsam mit der Bildklasse. Hier lernt der Algorithmus nicht, die Objekte zu unterscheiden, sondern diese Eigenschaften. Auch dies wird anhand der oben genannten Analogie deutlich: Der Schüler würde in diesem Fall etwa lernen, dass bei Multiple-Choice-Tests die längsten Antworten mit hoher Wahrscheinlichkeit richtig sind – was auch tatsächlich der Fall ist. Für die Bildverarbeitung bedeutet dies: Die Bilder von defektfreien Teilen können beispielsweise aus einem Produktionsszenario stammen, während die Bilder von fehlerbehafteten Objekten aus dem Labor mit anderer Beleuchtung und einem abweichenden Grauwert als Hintergrund kommen. Die Deep-Learning-Toolchain sollte in der Lage sein, solche Fälle verlässlich aufzuspüren. Möglich ist dies mit einer Heatmap, welche die für die Klassifizierung ausschlaggebenden Regionen eines Bildes deutlich hervorhebt.
Ein weiteres hilfreiches Feature ist das sogenannte Smart Labeling: Denn vor allem bei der Segmentierung gestaltet sich das Labeling sehr aufwändig, da hier Pixelregionen einer bestimmten Klasse zugeordnet werden müssen. Dies erfordert ein hohes Maß an manueller Arbeit mit Pinsel und Radierer. Die Deep-Learning-Toolchain sollte daher in der Lage sein, automatische Label-Vorschläge zu generieren. Wird das zu erkennende Objekt mit einer Bounding Box umrahmt, kann das Deep Learning Tool mit dieser zusätzlichen Information und dem KI-basierten Smart Labeling den Gegenstand automatisch segmentieren. Je nach Anwendungsfall spart dies sehr viel Zeit. Die Vorschläge lassen sich dann bei Bedarf manuell verbessern.
Autor
Christian Eckstein, Produktmanager Deep Learning Tool bei MVTec Software




