Kleine Geschichte der Künstlichen Intelligenz

Hatten Sie schon einmal das Gefühl, dass Sie das Thema Künstliche Intelligenz (KI) überwältigt; Dass Sie dessen weitläufige Terminologie nicht vollständig erfassen; und dass Sie die falschen Begriffe verwenden, wenn Sie über KI sprechen? Und hatten Sie auch schon einmal den Verdacht, dass es anderen ebenso geht?
Falls Sie diese Fragen mit „Ja“ beantworten, sind Sie nicht allein. KI ist derzeit der wahrscheinlich beliebteste Begriff der technologischen Agenda und es umgibt ihn, wie häufig bei beliebten Begriffen, einen Schleier der Zweideutigkeit. Zumal sich die Bandbreite an Anwendungen vom freundlichen digitalen Assistenten auf dem Handy bis hin zur Genomikforschung im Labor erstreckt. Sie alle haben den praktischen Wert von KI bereits bestätigt. Ausgestattet mit Deep-Learning-Fähigkeiten haben KI-fähige Systeme verschiedene Möglichkeiten, um mit ihrer Umgebung zu interagieren:
- Die Verarbeitung natürlicher Sprache nutzt virtuelle Assistenten und Chatbots, um die menschliche Stimme und geschriebenen Text zu analysieren und darauf zu reagieren.
- Bildverarbeitung ermöglicht das Analysieren großer Bilderarchive durch Klassifizierungssystemen, zum Beispiel Google Fotos, sowie die Echtzeitinteraktion autonomer Fahrzeuge und Roboterassistenten mit ihrer Umgebung.
- Im Bereich Mensch-Roboter-Interaktion werden Lösungen für die Zusammenarbeit mit KI erforscht und entwickelt, und zwar in Form ausgefeilter, vom Gehirn inspirierter Gehirn-Computer-Schnittstellen oder mit physischen Teilen ausgestatteter Roboter. Dennoch sind sich vermeintliche oder tatsächliche Experten, wie Forscher, Stellenvermittler und KI-Praktiker, bis heute bei vielen KI-bezogenen Fragen uneins. Dies ist einer der Gründe, warum das Thema für so viel Verwirrung sorgt. Um die Einzelheiten zu verstehen, müssen wir zuerst einen Schritt zurückgehen ...
Eine ganz kurze Geschichte der künstlichen Intelligenz
Obwohl KI-Anwendungen erst seit Kurzem so viel von sich reden machen, erhielte man durch das alleinige Betrachten der neuesten Trends beim maschinellen Lernen ein unvollständiges Bild und würde diese Wissenschaft nur teilweise verstehen. Um zu begreifen, wie ein Computer zu seinen Ergebnissen kommt, müssen wir uns ein wenig in die Geschichte der Mensch-Maschine-Beziehung vertiefen.
Die Fähigkeit, uns künstliches Leben vorzustellen, ist viele tausend Jahre älter als die Fähigkeit, es herzustellen. Antike Mythen wie Talos, ein von den Göttern hergestellter Mann aus Bronze, der die Insel Kreta schützen sollte, deutet darauf hin, dass das Konzept des Roboters den Menschen schon seit Langem inspiriert und oft erschreckt hat.
Doch bevor wir uns mit der Umsetzung dieser Ideen befassen, drängt uns die Erfahrung mit dem eigenen menschlichen Intellekt wahrscheinlich zu der Frage: Wenn Maschinen tatsächlich denken, welche Art Sprache verwenden sie dann?
Die Mathematik war schon lange die Sprache für logische Formeln, doch im 20. Jahrhundert ging es richtig zur Sache: Menschliche Sprachen hielt man für unvollständig und verwirrend. Mathematiker und Philosophen wie David Hilbert und Bernard Russell glaubten, dass eine mathematikbasierte Sprache notwendig war, um alle rationalen menschlichen Gedanken zu erfassen.
Erst im 20. Jahrhundert und mit dem Einzug von Alan Turing in die mathematische Logik führte die Suche nach dieser Sprache zum Bau einer theoretischen Maschine, die jedes ihr vorgestellte Logikproblem lösen konnte. Es war die Geburtsstunde der Informatik, deren Teilbereich die KI ist. Auf einem soliden mathematischen Fundament gegründet, das gelegentlich erschüttert wurde, gedieh die KI auch weiterhin und entwickelte sich dabei langsam weg von ihren rein mathematischen Wurzeln hin zu angewandten Ansätzen.
Die „künstliche Intelligenz“ als Begriff und Wissenschaft entstand 1956 im Dartmouth-Workshop. In einer wegweisenden Abhandlung definierten die Gründungsväter der KI sie als Streben nach dem Bau von Maschinen, die so intelligent sind wie wir: Sie „verwenden Sprache, bilden Abstraktionen und Konzepte, lösen alle Arten von Problemen, die derzeit noch dem Menschen vorbehalten sind, und verbessern sich selbst.“
Industrie und Wissenschaft waren von dieser vielversprechenden Technologie zunächst begeistert. Doch weil die praktischen Schwierigkeiten mit der KI unterschätzt wurden, kam es zu einer unrealistischen Erwartungshaltung. Beispielsweise stellte 1966 einer der Gründer, Marvin Minksy vom MIT, zusammen mit Seymour Papert, ein paar Studierende im Grundstudium die Aufgabe eines „Sommervisionsprojekts“, bei dem eine Kamera mit einem Computer verbunden werden sollte, um Muster zu erkennen und sogar Objekte in einer Szenerie zu identifizieren. Auch 56 Jahre später ist diese Aufgabe noch lange nicht gelöst. Diese Ungleichheit zwischen Möglichkeit und Realität führte manchmal zu Enttäuschung und zur im Nachhinein als „KI-Winter“ bezeichnete Phase stark gekürzter Finanzmittel für dieses Forschungsgebiet.
Heutzutage floriert die KI-Forschung. Doch es gibt noch immer erhebliche Einschränkungen, die die Wissenschaftler überwinden müssen. Diese Einschränkungen zeigen sich primär, wenn die KI mit der physischen Welt interagiert, da Roboter blamabel schlecht bei einfachen Aufgaben abschneiden, wie beim Öffnen einer Tür. Obwohl wir die Geschichte nur im Nachhinein beurteilen können, bedeutet die Tatsache, dass der Turing-Preis vor Kurzem drei bekannten KI-Forschern verliehen wurde, dass die Wissenschaftswelt die KI als ausgereiften, etablierten Teilbereich der Informatik ansieht.
Was man unter „KI“ verstehen kann
Heutzutage hat sich die Definition der KI in zwei verwandte, jedoch deutlich abgegrenzte Konzepte entwickelt. „Starke KI“ ist ein eher philosophisches und anhaltendes Streben nach der Entwicklung von Maschinen mit einem Bewusstsein. „Schwache KI“ andererseits stellt einen praktischeren Ansatz dar. Hier sollen Computerprogramme dazu gebracht werden, ohne menschliche Anleitung eine Aufgabe gut zu erledigen, von der angenommen wird, dass sie eine gewisse Intelligenz voraussetzt.
Obwohl wir sagen können, dass moderne Anwendungen des maschinellen Lernens das Stadium der schwachen KI erreicht haben, ist dies bei starker KI noch lange nicht so weit. Dies liegt an einem Phänomen namens „KI-Effekt“: Tragen wir einer Maschine eine Aufgabe auf, die Denken erfordert, beispielsweise Schach, und die Maschine löst diese Aufgabe, nimmt man ihr die magische Aura, die sie zuvor umgeben hat, und erachtet das Ganze später als reine Mechanik. Rodney Brooks, der frühere Leiter des MIT Artificial Intelligence Laboratory: „Jedes Mal, wenn wir eine weitere Lösung gefunden haben, ist es nicht mehr magisch. Wir sagen, ‚Ach, es ist nur eine Berechnung‘.“ Oder Larry Tesler, der im Stanford Artificial Intelligence Laboratory sowie bei Xerox PARC, Apple und Amazon gearbeitet hat: „Intelligenz ist all das, was Maschinen noch nicht getan haben“.
Gibt es einen Unterschied zwischen maschinellem Lernen und Statistik?
Das könnte eine kontroverse Frage sein, wie man sie in Online-Frage-Antwort-Foren findet, wo Definition und Inhalte des jungen und immer größer werdenden Bereichs des maschinellen Lernens (ML) heiß diskutiert werden. Statistiker charakterisieren ML häufig als glorifizierte Statistik, während ML-Praktiker die Statistik als veraltete Wissenschaft der Unbrauchbarkeiten bezeichnen. Die Wahrheit liegt, wie immer, irgendwo in der Mitte.
Maschinelles Lernen beruht auf der Statistik und verwendet bislang noch viele ihrer Werkzeuge. Das ist nur natürlich, da es das Ziel des ML ist, große Datenmengen zu analysieren, ihre statistischen Eigenschaften abzuleiten und daraus zu lernen, wie ähnliche Probleme im Zukunft gelöst werden könnten.
Nichtsdestotrotz hat sich die Forschung zum maschinellen Lernen weiter spezialisiert, da sich das Problem, einer Maschine das Lösen von Problemen beizubringen, in vielerlei Hinsicht von klassischen Fragestellungen in der Statistik unterscheidet. Während in der Statistik für gewöhnlich theoretische Probleme unter unrealistischen Annahmen gelöst werden, legt maschinelles Lernen den Fokus auf die Anwendung. Daher sind Aspekte wie Rechenaufwand, eine endliche Größe der verfügbaren Daten und Techniken für mehr Effizienz bei der Ausführungszeit, wie Parallelisierung anhand von GPUs (Graphical Processing Units und spezialisierte Softwarebibliotheken, die Eckpfeiler der heutigen Forschung zum maschinellen Lernen.
Wann wurde aus maschinellem Lernen Deep Learing?
Der Übergang vom maschinellen Lernen zum Deep Learning fand 2006 statt, wie die Heilige Schrift des Deep Learning berichtet. Obwohl der Begriff Deep Learning schon in den 40er-Jahren verwendet wurde, begannen das immense wissenschaftliche Interesse und industrielle Anwenden erst vor Kurzem – und die Revolution ist noch immer im Gange.
Beim maschinellen Lernen kommen verschiedene mathematische Modelle zum Einsatz, um die Lernaufgabe durchzuführen, doch beim Deep Learning setzt man hauptsächlich auf künstliche neuronale Netze (KNN). Der Grund, warum man diese Modelle heute als „tief“ bezeichnet, liegt darin, dass sie aufgrund verschiedener Verständnisebenen, die nach und nach zu einem tieferen Verständnis der beteiligten Konzepte führen, schwierige Probleme lösen können.
Früher mussten Datenwissenschaftler ihre Daten mit riesigem Aufwand verarbeiten, bevor sie sie dem Programm übergaben. Doch moderne KI-Systeme können mit Echtzeitdaten arbeiten. Virtuelle Assistenten verstehen menschliche Stimmen, autonome Fahrzeuge beobachten ihre Umgebung und reagieren schnell auf Unfälle, während Google Translate überraschend gut mit Ihren Texten umgeht – und das alles dank des angewandten Deep Learning.
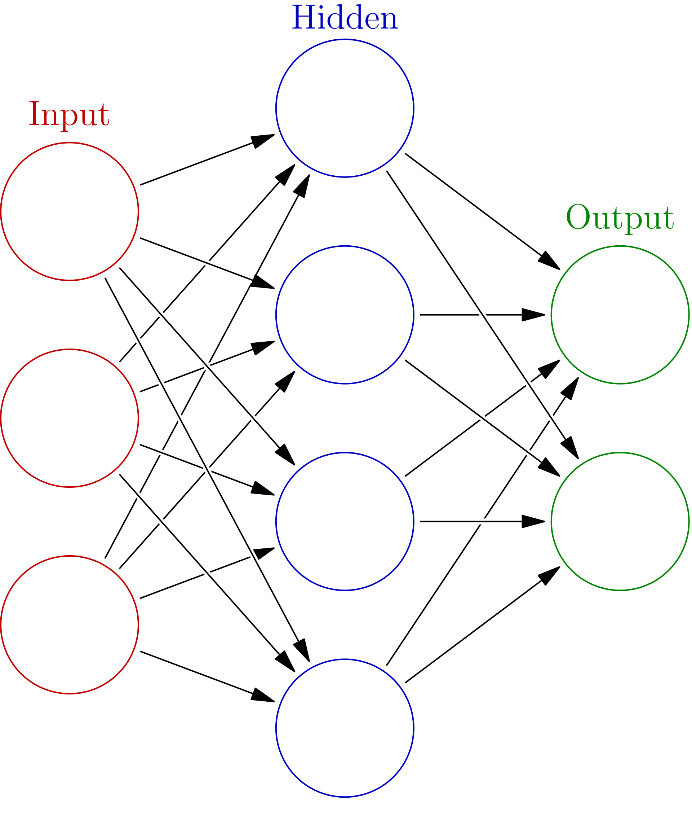
Künstliche neuronale Netze und Katzen
Da sie im Kern jedes Deep-Learning-Systems stehen, verdienen künstliche neuronale Netze einen genaueren Blick, um die interne Funktionsweise der KI zu verstehen. Obwohl ihre Struktur an biologische neuronale Netze angelehnt ist, kann es ein wenig irreführend sein, sie sich als künstliches Gehirn vorzustellen.
KNN verkörpern die langjährige KI-Idee des Konnektionismus: Es ist möglich, fortschrittlich intelligentes Verhalten rein anhand einer großen Anzahl einfacher Recheneinheiten zu simulieren. Diese Einheiten nennt man künstliche Neuronen. Man kann sie sich als einfaches Neuron vorstellen, das eine Eingabe akzeptiert und damit eine mathematische Operation ausführt, um eine Ausgabe zu generieren. Verbindet man Neuronen miteinander, erhält man das neuronale Netz. Es ist normalerweise in mehreren aufeinanderfolgenden Ebenen angeordnet, sodass der Eingang einer Ebene der Ausgang der folgenden ist. In dieser Hinsicht ist ein KNN ein komplexes mathematische Modell in Form eines Graphen.
Die KI-Forschung hat sich schon lange von der Neurobiologie getrennt. Die heutigen Erfolge verdanken wir weniger einem besseren Verständnis des menschlichen Gehirns, sondern vielmehr der Hardwarebeschleunigung und Entdeckungen der Informatik. Doch trotz seiner einfachen Struktur und Funktionsweise kann sich ein modernes KNN Bilder ansehen, alle darin enthaltenen Katzen finden und sogar Bilder von Katzen erzeugen, ohne je eine echte Katze gesehen zu haben. Das ist keine schwarze Magie, sondern Deep Learning.
Die Grundidee ist, dass wir vielleicht nicht verstehen, wie sich eine Aufgabe vollständig läsen lässt, doch wir können sie in Einzelschritte aufschlüsseln und hangeln uns so nach und nach in Richtung Ziel. Wenn wir ein Foto analysieren, denken wir anders als Maschinen. Wo wir Gegenstände und Farben sehen, nehmen Maschinen nur zweidimensionale Anordnungen von Pixelwerten wahr, die die Lichtintensität in anderen Teilen des Bildes quantifizieren. In Anwendungen mit Bildverarbeitung, dem Bereich der KI, in dem es um das Verstehen visueller Informationen geht, hat Deep Learning nicht nur Verbesserungen gebracht, sondern sie erst ermöglicht.
Bereits in den 1950er-Jahren deckten Biologieexperimente auf, dass Neuronen im Tiergehirn auf einfache geometrische Muster reagieren. Die moderne Anwendung des Deep Learning bestätigt dieses Prinzip: Ein Deep-Learning-KNN verwendet seine erste Ebene, um Punkte und Linien zu erkennen, die nächsten Ebenen dann zum Auffinden komplexerer geometrischer Formen und die tieferen Ebenen zur Kategorisierung dieser Formen in Konzepte, beispielsweise Katzen. Durch das Trainieren des Netzes mit Millionen von Bildern verschiedener Inhalte kann das Netz das Konzept der Katze erlernen und damit eigene, manchmal ungewöhnliche Katzenbilder erzeugen.
Es ist eine Daten-essen-Daten-Welt
Trotz der immensen Weiterentwicklungen bei KI-Techniken, Softwarebibliotheken und Hardware gibt es bei jedem KI-Projekt einen schwer zu steuernden Paramater: Daten. Je tiefer die verwendeten Netze sind, desto mehr Daten werden nötig, damit das System die statistischen Eigenschaften des Problems richtig erkennt.
Da Daten normalerweise vom Onlineverhalten der Anwender generiert werden, beispielsweise ihrer Präsenz in sozialen Medien und ihrer in die Cloud hochgeladenen, privaten Bilder, kann man sich leicht vorstellen, warum technologische Giganten wie Amazon, Google und IBM verschiedene Produkte mit personalisiertem Nutzungskomfort eingeführt haben. Das ungebrochene Wachstum dieser Unternehmen lässt sich durch ein Phänomen erklären, das Marktexperten als Erfolgsspirale bezeichnen: Je mehr Daten einem Unternehmen zur Verfügung stehen, desto besser sind die angebotenen KI-Dienste, wodurch die Anwender eher bereit sind, diese Dienste zu nutzen, und daher mehr Daten generieren, die das Unternehmen zur Verbesserung der Dienste nutzen kann.
Als riesiger und äußerst beliebter Bereich ist es nur natürlich, dass es bei der KI zu etlichen Missverständnissen kommt. Dies wiederum kann zu einem gewissen Unbehagen, ja sogar zu Angst vor ihrer möglichen Macht und Wirkung auf die Gesellschaft führen, was Aussagen erklärt wie Stephen Hawkings prophetische Äußerung, dass „die Entwicklung umfassender künstlicher Intelligenz das Ende der menschlichen Rasse bedeuten könnte“. Während Hawking über starke KI sprach, näherte sich Steve Jobs der Technologie eher mit einer angewandte, am Menschen orientierten Haltung, als er sagte, dass „Computer Fahrräder für das menschliche Gedächtnis sind“.
Position zu beziehen, ist nicht einfach. Eines jedoch ist sicher: KI ist eine Technologie, die die Gesellschaft verändern wird – beziehungsweise es bereits tut. Wie bei allen gesellschaftlichen Phänomenen muss man auch beim Entwickeln einer verantwortungsbewussten Haltung zur KI hinter den Schleier der Verwirrung blicken und die Hintergründe und Eigenheiten dieses spannenden Bereichs in ihrer Gesamtheit verstehen.
Anbieter
Teledyne DALSA GmbHLise-Meitner-Str. 7
82152 Krailling
Deutschland





Meist gelesen

Intelligente Greiflösungen für die Automation von morgen
Mechatronische Systeme für maximale Bewegungsfreiheit, präzise Steuerung und hohe Sicherheit in anspruchsvollen Automatisierungsprozessen.

Warum Autovimation der Exaktera-Gruppe beitrat
Peter Neuhaus erläutert die Beweggründe für den Verkauf von Autovimation an Exaktera. Im Vordergrund stand die strategische Weiterentwicklung durch internationale Vertriebsstrukturen und zusätzliche Marketingressourcen.

Supercaps: Die bessere Alternative zur Batterie?
Bei welchen Anwendungen liegen Supercaps vorn und was sind deren Vorteile?

Revolutioniert der DCC die Messtechnik?
Digitaler Kalibrierschein (DCC) für
Mehrkomponentenaufnehmer

AR-gestützte Qualitätskontrolle von Kranteilen
Bauteilprüfung mit Augmented Reality direkt in der Fertigung