„Die Komplexität der Deep- Learning-Nutzung muss sinken“
Wie lässt sich der Einsatz von künstlicher Intelligenz vereinfachen? Christian Eckstein von MVTec erläutert im Interview die größten Hindernisse und mögliche Lösungen. Außerdem stellt er eine neue KI-Funktion vor, die bei der Inspektion selbstständig den Kontext miteinbezieht, um so beispielweise vertauschte Etiketten zu erkennen.
inspect: Derzeit erlebt künstliche Intelligenz und darin vor allem Deep Learning einen mega Hype. Warum?
Christian Eckstein: Künstliche Intelligenz (KI) erlebt in der Tat derzeit einen wahren Boom und erntet sehr viel Aufmerksamkeit in Wirtschaft und Gesellschaft. Dies resultiert vor allem daraus, dass KI-Anwendungen im Alltagsleben der Menschen mittlerweile eine wichtige Rolle spielen. Ob digitale Assistenten, Übersetzungsmaschinen, Spracherkennungs-Software oder selbstfahrende Autos – in vielen Fällen lassen sich mit den intelligenten Algorithmen Prozesse nicht nur optimieren, sondern nahezu revolutionieren. Eine ähnliche Wirkung – aber in etwas abgeschwächter Form – entfaltet KI und insbesondere Deep Learning bei Machine-vision-basierten Inspektionsaufgaben. Hier werden mithilfe der Technologie besonders robuste, bislang nicht erreichte Erkennungsergebnisse erzielt.
Der Grund hierfür liegt in dem Ansatz selbstlernender Systeme. Deutlich wird dies an einer Analogie aus einem Lebensbereich, den wir alle aus unserer Kindheit und Jugend kennen – der Schule: Muss der Schüler hier eine Aufgabe lösen, würde er bei einem klassischen Ansatz einem vorgegebenen Weg folgen. Anders bei einem selbstlernenden Verfahren: Hier würde er mit einer Vielzahl vergleichbarer Aufgaben und deren Lösungen in einem iterativen Prozess selbst den richtigen Weg finden – was einen grundlegenden Unterschied bedeutet. Und genauso verhält es sich in der industriellen Bildverarbeitung: Während bei traditionellen Ansätzen explizit Eigenschaften eines Bildes beschrieben und verarbeitet werden, steht bei Deep Learning – wie der Name schon sagt – ein Lernprozess im Mittelpunkt. So werden mithilfe großer Mengen von Bilddatensätzen neuronale Netze umfassend trainiert. Auf dieser Basis lassen sich dann die relevanten Bildeigenschaften gezielt identifizieren und auswerten. Diese Methodik ermöglicht herausragende Identifikationsraten und ebnet den Weg für ganz neue Inspektionsanwendungen, die sich mit Machine Vision bisher so nicht realisieren ließen.

inspect: Warum bleibt dennoch der Run seitens der Anwender aus?
Eckstein: Hierfür gibt es mehrere Gründe. Der wichtigste besteht jedoch in der hohen Komplexität der Technologie. So wird – je nach Anwendung – oft eine sehr große Menge valider Bilddaten benötigt, um ein effektives Training und damit brauchbare Inspektionsergebnisse zu erzielen. Die Erzeugung dieser Bilder ist mit einem enormen Aufwand verbunden, den viele Unternehmen kaum stemmen können. Dabei geht es nicht nur um die Beschaffung. Ebenso ist es erforderlich, die Bilder vor Beginn des eigentlichen Trainingsprozesses zu labeln, also mit einem digitalen Etikett zu versehen. Auch dies kostet bei einer entsprechend hohen Anzahl von Bilddatendatensätzen viel Zeit und Mühe. Dazu kommt: Eine reguläre Machine-Vision-Software setzt voraus, dass die Trainingsbilder das entsprechende Objekt mitsamt dem zu findenden Fehler zeigen. Das bedeutet, Anwender müssen diese sogenannten „Schlecht-Bilder“ erst generieren, was zusätzlichen Aufwand verursacht.
Ein weiterer Grund für die verhaltene Nachfrage nach Deep-Learning-basierten Lösungen ist in dem hohen Bedarf an System-Performance und Speicherkapazitäten zu sehen. So ist zur Verarbeitung der großen Datenmengen eine enorme Rechenleistung nötig, die entsprechende Hardware-Kosten nach sich zieht. Und schließlich hält mitunter auch die mangelnde Transparenz von Deep-Learning-Prozessen Industrieunternehmen davon ab, in solche Systeme zu investieren. Denn ein neuronales Netzwerk ist in der Regel als „Black Box“ konzipiert, die sich von außen kaum einsehen lässt. Deshalb ist es schwierig, die internen Vorgänge lückenlos nachzuvollziehen.
Kommt der alleinige Einsatz eines Deep-Learning-Systems aus den genannten Gründen nicht in Betracht, kann die KI-Technologie aber auch mit traditionellen, regelbasierten Bildverarbeitungsverfahren kombiniert werden. Mit dieser zweigleisigen Lösung lassen sich dann auch anspruchsvolle Inspektionsaufgaben zufriedenstellend meistern.
inspect: Wie lässt sich der Einsatz von künstlicher Intelligenz vereinfachen?
Eckstein: Die Nutzung von Deep-Learning-Technologien wird für die Anwender dann einfacher, wenn sie den Aufwand für die Bereitstellung der Trainingsbilder maßgeblich reduzieren können. Möglich ist dies beispielsweise mit unserem KI-basierten Feature „Anomaly Detection“: Hiermit sind für das Training nur mehr Bilder erforderlich, die den jeweiligen Gegenstand in fehlerfreiem Zustand zeigen. Solche sogenannten „Gut-Bilder“ lassen sich nicht nur deutlich einfacher bereitstellen als die erwähnten „Schlecht-Bilder“. Auch können Anomalien in Farbe, Struktur oder sonstiger Beschaffenheit verlässlich gefunden werden, deren Erscheinungsbild vorher nicht bekannt ist. Zudem entfällt fast der gesamte Labeling-Prozess, da auf den Bildern ja keine Fehler mehr zu sehen sind. Darüber hinaus benötigt die „Anomaly-Detection“-Technologie für das Training erheblich weniger Bilder als konventionelle, KI-basierte Inspektionsalgorithmen. Bereits 20 Aufnahmen können ausreichen, um robuste Erkennungsraten zu erzielen. Alle diese Vorteile sind aber nur ein Beispiel dafür, den Aufwand für die KI-basierte Fehlerinspektion zu verringern und damit die Effizienz der Qualitätssicherung entscheidend zu steigern.
inspect: Die auf Deep Learning basierende Halcon-Funktion „Anomaly Detection“ wurde im Release 22.05 um die „Global Context Anomaly Detection“ erweitert. Wo genau liegen die Unterschiede?
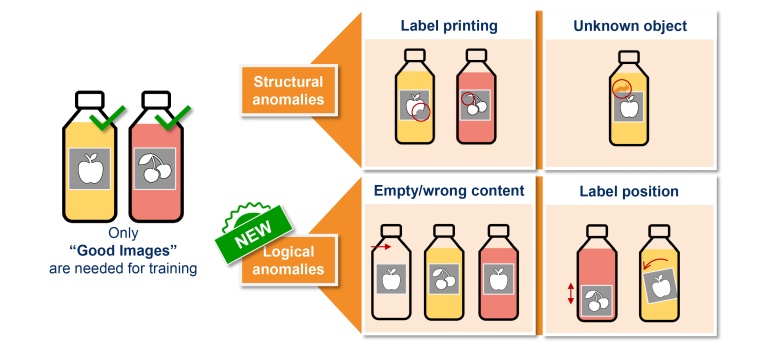
Eckstein: Das Feature „Global Context Anomaly Detection“ hebt die Deep-Learning-basierte Defekterkennung auf eine neue Stufe: Bisher ließen sich mit der Vorgänger-Technologie „Anomaly Detection“ lediglich lokal begrenzte, strukturelle Anomalien erkennen. Die erweiterte Technologie ist nun in der Lage, komplett unbekannte Varianten von Fehlern wie beispielsweise fehlende, verformte oder falsch angeordnete Bauteile zielsicher zu erkennen. Somit ist die Fehlerinspektion nicht mehr auf die bloße Identifikation lokaler Anomalien beschränkt. Vielmehr können nun auch logische Inhalte des gesamten Bildes umfassend „verstanden“ werden. Das ist in dieser Form weltweit bislang einzigartig und ebnet erstmalig den Weg für eine inhaltliche und logische Qualitätskontrolle.
Dadurch können noch anspruchsvollere Aufgaben für verschiedenste Industriebranchen praktikabel umgesetzt werden. Beispielsweise lässt sich damit die Prüfung von Aufdrucken und Etiketten auf Produkten optimieren. Und auch die Elektronikindustrie profitiert von „Global Context Anomaly Detection“: So werden etwa bei der Inspektion von Leiterplatten in der Halbleiterfertigung deutlich robustere Fehlererkennungsraten erreicht.
inspect: Welche Anwendungen werden damit nun zusätzlich umsetzbar?
Eckstein: „Global Context Anomaly Detection“ macht den Weg frei für eine neue Dimension Machine-vision-basierter Anwendungen in der Fehlerinspektion: Beispielsweise können Getränkeabfüller ihre Flaschen nun noch umfassender prüfen. Während Anomaly Detection Defekte auf dem Etikett oder Schäden an der Flasche erkennt, kann das erweiterte Feature inhaltliche und logische Fehler lernen und entsprechend verlässlich identifizieren. So ist die Technologie etwa in der Lage, den Zusammenhang zwischen Inhalt und Etikett des Behälters zu verstehen. Dabei wird beispielsweise zu einem Kirschsaft ein Logo mit einer roten Kirsche in Beziehung gesetzt. Eine Banane auf dem Etikett der Kirschsaftflasche würde demnach als Fehler erkannt. Auch ein Label in falscher Position kann nun als Defekt eingestuft werden.
Auch jenseits der Getränkeindustrie leistet die logische Fehlererkennung in zahlreichen weiteren Applikationen wertvolle Dienste: So kann die neue Technologie fehlende oder falsch positionierte Bauteile auf Leiterplatten sowie fehlende Beschriftungen verlässlich identifizieren und die Produkte auf Vollständigkeit überprüfen. Dabei lernt das Feature anhand von Trainingsdaten eigenständig die korrekte Menge beispielsweise von Schrauben und Muttern in einer Packung – und schlägt bei einer falschen Stückzahl sofort Alarm. Derartige Anwendungen waren bisher zwar möglich, erforderten aber einen hohen Programmieraufwand. Dieser lässt sich nun deutlich verringern, da ein Training mit Halcon22.05 je nach Applikation nur wenige hundert „Gut-Bilder“ benötigt. Dabei nimmt der Trainingsprozess nur wenige Stunden in Anspruch.
Autor
David Löh, Chefredakteur der inspect
Anbieter
MVTec Software GmbHArnulfstraße 205
80634 München
Deutschland




Meist gelesen

Echtzeit-Analyse mit KI-gesteuerten Hyperspektralkameras
Hyperspektrale Bildgebung gilt als Schlüsseltechnologie in Einsatzgebieten, in denen neben der visuellen Erscheinung auch die Materialzusammensetzung von Objekten eine Rolle spielt.

Es muss nicht immer ein humanoider Roboter sein
Mythomorphes Design eröffnet der sozialen Robotik eine eigene Perspektive. Als Vorbilder dienen Mythen und Fantasiewesen statt Mensch oder Tier. Der Beitrag ordnet Beispiele ein und diskutiert Chancen sowie Risiken.
Chatbots für tote, gefährdete und ausgestorbene Sprachen
Möglichkeiten und Grenzen generativer KI für die Weiterbildung.

Humanoide Roboter erreichen den Mittelstand
Sinkende Kosten, schnelle Einsatzbereitschaft und steigende Flexibilität eröffnen neue Anwendungen jenseits klassischer Insellösungen.

Die Zukunft der Intralogistik
Die Intralogistik befindet sich im Wandel: Der Bedarf an qualifizierten Fachkräften steigt, während gleichzeitig neue Konzepte und Technologien entstehen.